A few weeks ago, I blogged about the problems we had with TCP at this year's TG, how TCP's bursty behavior causes problems when you stream from a server that has too much bandwidth comparing to your clients, and how all of this ties into bufferbloat. I also promised a followup. I wish I could say this post would be giving you all the answers, but to be honest, it leaves most of the questions unanswered. Not to let that deter us, though :-)
To recap, recall this YouTube video which is how I wanted my TCP video streams to look:
(For some reason, it gets messed up on Planet Debian, I think. Follow the link to my blog itself to get the video if it doesn't work for you.)
So, perfect nice and smooth streaming; none of the bursting that otherwise is TCP's hallmark. However, I've since been told that this is a bit too extreme; you actually want some bursting, counterintuitively enough.
There are two main reasons for this: First, the pragmatic one; if you do bigger bursts, you can use TCP segmentation offload and reduce the amount of work your CPU needs to do. This probably doesn't matter that much for 1 Gbit/sec anymore, but for 10 Gbit/sec, it might.
The second one is a bit more subtle; the argument goes about as follows: Since packets are typically sent in bursts, packet loss typically also occurs in bursts. Given that TCP cares more about number of loss events than actual packets lost (losing five packets in a row is not a lot worse than losing just one packet, but losing a packet each on five distinct occasions certainly can be), you'd rather take your losses in a concentrated fashion (ie., in bursts) than spread out randomly between all your packets.
So, how bursty should you be? l did some informal testing—I sent bursts of varying sizes (all with 1200-byte UDP packets, with enough spacing between the bursts that they would be independent) between 1 Gbit/sec in Trondheim and 30 Mbit/sec in Oslo, and on that specific path, bursts below six or seven packets always got through without loss. Then there would be some loss up to 30–50 packets, where the losses would start to skyrocket. (Bursts of 500 packets would never get through without a loss—seemingly I exhausted the buffer of some downconverting router or switch along the path.) I have to stress that this is very unscientific and only holds for that one specific path, but based on this, my current best estimate is that bursts of 8 kB or so (that's 5–6 1500-byte packets) should be pretty safe.
So, with that in mind, how do we achieve the pacing panacea? I noted last time that mainline Linux has no pacing, and that still holds true—and I haven't tried anything external. Instead, I wanted to test using Linux' traffic control (tc) to rate-limit the stream; it messes with TCP's estimation of the RTT since some packets are delayed a lot longer than others, but that's a minor problem compared to over-burstiness. (Some would argue that I should actually be dropping packets instead of delaying them in this long queue, but I'm not actually trying to get TCP to send less data, just do it in a less bursty fashion. Dropping packets would make TCP send things just as bursty, just in smaller bursts; without a queue, the data rate would pretty soon go to zero.)
Unfortunately, as many others will tell you, tc is an absurdly complex mess. There are something like four HOWTOs and I couldn't make heads or tails out of them, there are lots of magic constants, parts are underdocumented, and nobody documents their example scripts. So it's all awesome; I mean, I already feel like I have a handle of Cisco's version of this (at least partially), but qdiscs and classes and filters and what the heck? There always seemed to be one component too many for me in the puzzle, and even though there seemed to be some kind of tree, I was never really sure whether packets flowed down or up the tree. (Turns out, they flow first down, and then up again.)
Eventually I think I understand tc's base model, though; I summarized it in this beautiful figure:
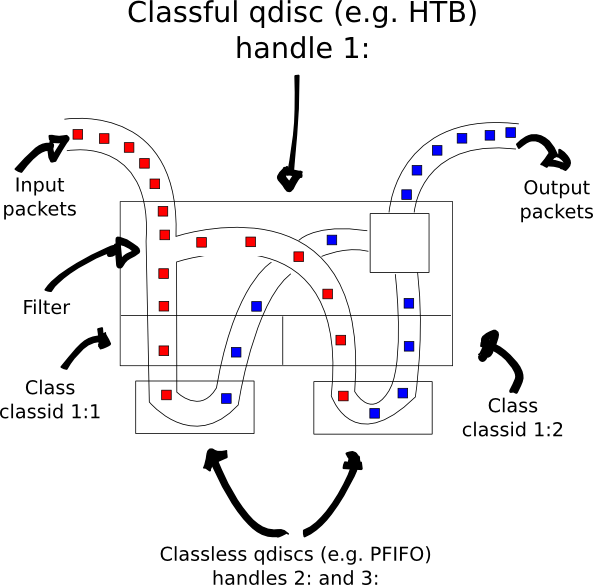
There are a few gotchas, though:
- Don't use CBQ unless you really have to. HTB is a lot simpler.
- tc's filtering is notoriously hard and limited, and seems to plain out not work in a lot of places. If you can at all, use iptables' MARK target to classify things (which allows you to do advanced things like, oh, select packets on port number without sacrificing a goat) and then use the mark filter in tc (which, confusingly enough, matches the iptables mark against the handle of the tc filter). Even so, I can't really find a way to chain filters in tc (e.g., if you do match mark 3, then try this other filter here).
My test setup uses the flow filter to hash each connection (based on source/destination IP address and TCP port) into one of 1024 buckets, shaped to 8 Mbit/sec or so (the video stream is 5 Mbit/sec, and then I allow for some local variation plus retransmit). That's the situation you see in the video; if I did this again (and I probably will soon), I'd probably allow for some burstiness as described earlier.
However, there's an obvious problem scaling this. Like I said, I hash each connection into one of 1024 buckets (I can scale to 16384, it seems, but not much further, as there are 16-bit IDs in the system), but as anybody who has heard about the birthday paradox will know, surprisingly soon you will find yourself with two connections in the same bucket; for 1024, you won't need more than about sqrt(1024) = 32 connections before the probability of that hits 50%.
Of course, we can add some leeway for that; instead of 8 Mbit/sec, we can choose 16, allowing for two streams. However, most people who talk about the birthday paradox don't seem to talk much about the possibility of three connections landing in the same bucket. I couldn't offhand find any calculations for it, but simple simulation showed that it happens depressingly often, so if you want to scale up to, say, a thousand clients, you can pretty much forget to use this kind of random hashing. (I mean, if you have to allow for ten connections in each bucket, shaping to 80 Mbit/sec, where's your smoothness win again?)
The only good way I can think of to get around this problem is to have some sort of cooperation from userspace. In particular, if you run VLC as root (or with the network administrator capability), you can use the SO_MARK socket option to set the fwmark directly from VLC, and then use the lower bits of that directly to choose bucket. That way, you could have VLC keep track of which HTB buckets were in use or not, and just put each new connection in an unused one, sidestepping the randomness problems in the birthday paradox entirely. (No, I don't have running code for this.) Of course, if everybody were on IPv6, you could use the flow label field for this—the RFC says load balancers etc. are not allowed to assume any special mathematical properties of this (20-bit) field, but since you're controlling both ends of the system (both VLC, setting the flow label, and the tc part that uses it for flow control) you can probably assume exactly what you want.
So, with that out of the way, at least in theory, let's go to a presumably less advanced topic. Up until now, I've mainly been talking about ways to keep TCP's congestion window up (by avoiding spurious packet drops, which invariably get the sender's TCP to reduce the congestion window). However, there's another window that also comes into play, which is much less magical: The TCP receive window.
When data is received on a TCP socket, it's put into a kernel-side buffer until the application is ready to pick it up (through recv() or read()). Every ACK packet contains an updated status of the amount of free space in the receive buffer, which is presumably the size of the buffer (which can change in modern TCP implementations, though) minus the amount of data the kernel is holding for the application.
If the buffer becomes full, the sender can do nothing but wait until the receiver says it's ready to get more; if the receiver at some point announces e.g. 4 kB free buffer space, the sender can send only 4 kB more and then has to wait. (Note that even if VLC immediately consumes the entire buffer and thus makes lots of space, the message that there is more space will still need to traverse the network before the sender can start to push data again.)
Thus, it's a bit suboptimal, and rather surprising, that VLC frequently lets there be a lot of data in the socket buffer. The exact circumstances under which this happens is a bit unclear to me, but the general root of the problem is that VLC doesn't distinguish between streaming a file from HTTP and streaming a live video stream over HTTP; in the former case, just reading in your own tempo is the simplest way to make sure you don't read in boatloads of data you're not going to play (although you could of course spill it to disk), but in the second one, you risk that the receive buffer gets so small that it impairs the TCP performance. Of course, if the total amount of buffering is big enough, maybe it doesn't matter, but again, remember that the socket buffer is not as easily emptied as an application-managed buffer—there's a significant delay in refilling it when you need that.
Fixing this in VLC seems to be hard—I've asked on the mailing list and the IRC channel, and there seems to be little interest in fixing it (most of the people originally writing the code seem to be long gone). There is actually code in there that tries to discover if the HTTP resource is a stream or not (e.g. by checking if the server identifies itself as “Icecast” or not; oddly enough, VLC itself is not checked for) and then empty the buffer immediately, but it is disabled since the rest of the clock synchronization code in VLC can't handle data coming in at such irregular rates. Also, Linux' receive buffer autotuning does not seem to handle this case—I don't really understand exactly how it is supposed to work (ie. what it reacts to), but it does not seem to react to the buffer oscillating between almost-full and almost-empty.
Interestingly enough, Flash, as broken as it might be in many other aspects, seems to have no such problem—it consistently advertises a large, constant (or near-constant) receive window, indicating that it empties its socket buffer in a timely fashion. (However, after a few minutes it usually freezes shortly for some unknown reason, causing the buffer to go full—and then it plays fine from that point on, with an even larger receive window, since the receive window autotuning has kicked in.) Thus, maybe you won't really need to care about the problem at all; it depends on your client. Also, you shouldn't worry overly much about this problem either, as most of the time, there seems to be sufficient buffer free that it doesn't negatively impact streaming. More research here would be good, though.
So, there you have it. We need: Either paced TCP in Linux or a more intelligent way of assigning flows to HTB classes, a VLC client with modified buffering for streaming, and possibly more aggressive TCP receive window autotuning. And then, all of this turned on by default and on everybody's machines. =)