With The Gathering 2013 well behind us, I
wanted to write a followup to the posts I had on video streaming earlier.
Some of you might recall that we identified an issue at TG12, where the video
streaming (to external users) suffered from us simply having too fast
network; bursting frames to users at 10 Gbit/sec overloads buffers in the
down-conversion to lower speeds, causing packet loss, which triggers new
bursts, sending the TCP connection into a spiral of death.
Lacking proper TCP pacing in the Linux kernel, the workaround was simple
but rather ugly: Set up a bunch of HTB buckets (literally thousands),
put each client in a different bucket, and shape each bucket to approximately
the stream bitrate (plus some wiggle room for retransmits and bitrate peaks,
although the latter are kept under control by the encoder settings).
This requires a fair amount of cooperation from VLC, which we use as both
encoder and reflector; it needs to assign a unique mark (fwmark) to each
connection, which then tc can use to put the client into the right HTB
bucket.
Although we didn't collect systematic user experience data (apart from my own
tests done earlier, streaming from Norway to Switzerland), it's pretty clear
that the effect was as hoped for: Users who had reported quality for a given
stream as “totally unusable” now reported it as “perfect”. (Well, at first
it didn't seem to have much effect, but that was due to packet loss caused by
a faulty switch supervisor module. Only shows that real-world testing can be
very tricky. :-) )
However, suddenly this happened on the stage:
which led to this happening to the stream load:
and users, especially ones external to the hall, reported things breaking up
again. It was obvious that the load (1300 clients, or about 2.1 Gbit/sec) had something to do
with it, but the server wasn't out of CPU—in fact, we killed a few other
streams and hung processes, freeing up three or so cores, without any effect.
So what was going on?
At the time, we really didn't get to go deep enough into it before the load
had lessened; perf didn't really give an obvious answer (even though HTB is
known to be a CPU hog, it didn't really figure high up in the list), and the
little tuning we tried (including removing HTB) didn't really help.
It wasn't before this weekend, when I finally got access to a lab with 10gig
equipment (thanks, Michael!), that I could verify my suspicions: VLC's HTTP server is
single-threaded, and not particularly efficient at that. In fact, on the lab
server, which is a bit slower than what we had at TG (4x2.0GHz Nehalem versus
6x3.2GHz Sandy Bridge), the most I could get from VLC was 900 Mbit/sec, not
2.1 Gbit/sec! Clearly we were both a bit lucky with our hardware, and that we
had more than one stream (VLC vs. Flash) to distribute our load on. HTB was
not the culprit, since this was run entirely without HTB, and the server
wasn't doing anything else at all.
(It should be said that this test is nowhere near 100% exact, since the
server was
only talking to one other machine, connected directly to the same switch,
but it would seem a very likely bottleneck, so in lieu of $100k worth of
testing equipment and/or a very complex netem setup, I'll accept it as
the explanation until proven otherwise. :-) )
So, how far can you go, without switching streaming platforms entirely?
The answer comes in form of
Cubemap, a replacement
reflector I've been writing over the last week or so. It's multi-threaded,
much more efficient (using epoll and sendfile—yes, sendfile), and also
is more robust due to being less intelligent (VLC needs to demux and remux
the entire signal to reflect it, which doesn't always go well for more
esoteric signals; in particular, we've seen issues with the Flash video mux).
Running Cubemap on the same server, with the same test client (which is
somewhat more powerful), gives a result of 12 Gbit/sec—clearly better than
900 Mbit/sec! (Each machine has two Intel 10Gbit/sec NICs connected with LACP
to the switch, and load-balance on TCP port number.) Granted, if you did this kind of test using real users, I doubt
they'd get a very good experience; it was dropping bytes like crazy since it
couldn't get the bytes quickly enough to the client (and I don't think it was
the client that was the problem, although that machine was also clearly very
very heavily loaded). At this point, the problem is
almost entirely about kernel scalability; less than 1% is spent in userspace,
and you need a fair amount of mucking around with multiple NIC queues to get
the right packets to the right processor without them stepping too much on
each others' toes. (Check out
/usr/src/linux/Documentation/network/scaling.txt
for some essential tips here.)
And now, finally, what happens if you enable our HTB setup? Unfortunately,
it doesn't really go well; the nice 12 Gbit/sec drops to 3.5–4 Gbit/sec!
Some of this is just increased amounts of packet processing (for instance,
the two iptables rules we need to mark non-video traffic alone take the
speed down from 12 to 8), but it also pretty much shows that HTB doesn't
scale: A lot of time is spent in locking routines, probably the different
CPUs fighting over locks on the HTB buckets. In a sense, it's maybe not
so surprising when you look at what HTB really does; you can't process
each packet as independently, the entire point is to delay packets based
on other packets. A more welcome result is that setting up a single fq_codel
qdisc on the interface hardly mattered at all; it went down from 12 to
11.7 or something, but inter-run variation was so high, this is basically
only noise. I have no idea if it actually had any effect at all, but it's
at least good to know that it doesn't do any harm.
So, the conclusion is: Using HTB to shape works well, but it doesn't
scale. (Nevertheless, I'll eventually post our scripts and the VLC patch
here. Have some patience, though; there's a lot of cleanup to do after
TG, and only so much time/energy.) Also, VLC only scales up to a thousand
clients or so; after that, you want Cubemap. Or Wowza. Or Adobe Media Server.
Or nginx-rtmp, if you want RTMP. Or… or… or… My head spins.
Sat, 02 Jun 2012 - TCP optimization for video streaming, part 2
A few weeks ago, I blogged about the problems we had with TCP at this year's TG,
how TCP's bursty behavior causes problems when you stream from a server
that has too much bandwidth comparing to your clients, and how all of this
ties into bufferbloat.
I also promised a followup. I wish I could say this post would be giving you all
the answers, but to be honest, it leaves most of the questions unanswered.
Not to let that deter us, though :-)
To recap, recall this YouTube video which is how I wanted my TCP video
streams to look:
(For some reason, it gets messed up on Planet Debian, I think. Follow the
link to my blog itself to get the video if it doesn't work for you.)
So, perfect nice and smooth streaming; none of the bursting that otherwise
is TCP's hallmark. However, I've since been told that this is a bit too
extreme; you actually want some bursting, counterintuitively enough.
There are two main reasons for this: First, the pragmatic one; if you do
bigger bursts, you can use TCP segmentation offload and reduce the amount
of work your CPU needs to do. This probably doesn't matter that much for
1 Gbit/sec anymore, but for 10 Gbit/sec, it might.
The second one is a bit more subtle; the argument goes about as follows:
Since packets are typically sent in bursts, packet loss typically also
occurs in bursts. Given that TCP cares more about number of loss events
than actual packets lost (losing five packets in a row is not a lot worse
than losing just one packet, but losing a packet each on five distinct occasions
certainly can be), you'd rather take your losses in a concentrated fashion
(ie., in bursts) than spread out randomly between all your packets.
So, how bursty should you be? l did some informal testing—I sent
bursts of varying sizes (all with 1200-byte UDP packets, with enough spacing
between the bursts that they would be independent) between 1 Gbit/sec in Trondheim and
30 Mbit/sec in Oslo, and on that specific path, bursts below six or seven packets always
got through without loss. Then there would be some loss up to 30–50
packets, where the losses would start to skyrocket. (Bursts of 500 packets
would never get through without a loss—seemingly I exhausted the
buffer of some downconverting router or switch along the path.) I have to
stress that this is very unscientific and only holds for that one specific
path, but based on this, my current best estimate is that bursts of 8 kB
or so (that's 5–6 1500-byte packets) should be pretty safe.
So, with that in mind, how do we achieve the pacing panacea? I noted last
time that mainline Linux has no pacing, and that still holds true—and
I haven't tried anything external. Instead, I wanted to test using Linux'
traffic control (tc) to rate-limit the stream; it messes with TCP's estimation
of the RTT since some packets are delayed a lot longer than others, but
that's a minor problem compared to over-burstiness. (Some would argue
that I should actually be dropping packets instead of delaying them in
this long queue, but I'm not actually trying to get TCP to send less
data, just do it in a less bursty fashion. Dropping packets would make
TCP send things just as bursty, just in smaller bursts; without a queue,
the data rate would pretty soon go to zero.)
Unfortunately, as many others will tell you, tc is an absurdly complex
mess. There are something like four HOWTOs and I couldn't make heads or
tails out of them, there are lots of magic constants, parts are
underdocumented, and nobody documents their example scripts. So it's
all awesome; I mean, I already feel like I have a handle of Cisco's
version of this (at least partially), but qdiscs and classes and filters
and what the heck? There always seemed to be one component too many for
me in the puzzle, and even though there seemed to be some kind of tree,
I was never really sure whether packets flowed down or up the tree.
(Turns out, they flow first down, and then up again.)
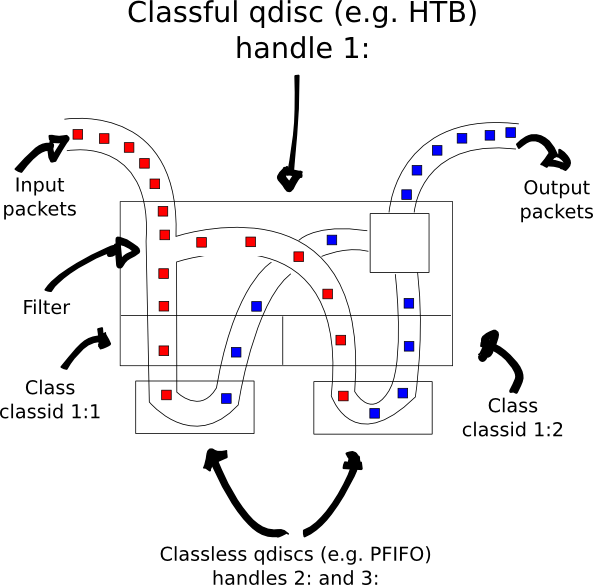
Eventually I think I understand tc's base model, though; I summarized
it in this beautiful figure:
There are a few gotchas, though:
Don't use CBQ unless you really have to. HTB is a lot simpler.
tc's filtering is notoriously hard and limited, and seems to plain
out not work in a lot of places. If you can at all, use iptables'
MARK target to classify things (which allows you to do advanced things like,
oh, select packets on port number without sacrificing a goat) and
then use the mark filter in tc (which, confusingly
enough, matches the iptables mark against the handle of the
tc filter). Even so, I can't really find a way to chain filters in
tc (e.g., if you do match mark 3, then try this other filter here).
My test setup uses the flow filter to hash each connection (based on
source/destination IP address and TCP port) into one of 1024 buckets,
shaped to 8 Mbit/sec or so (the video stream is 5 Mbit/sec, and then
I allow for some local variation plus retransmit). That's the situation
you see in the video; if I did this again (and I probably will soon), I'd
probably allow for some burstiness as described earlier.
However, there's an obvious problem scaling this. Like I said, I hash
each connection into one of 1024 buckets (I can scale to 16384, it
seems, but not much further, as there are 16-bit IDs in the system),
but as anybody who has heard about the birthday paradox will know,
surprisingly soon you will find yourself with two connections in the
same bucket; for 1024, you won't need more than about sqrt(1024) = 32
connections before the probability of that hits 50%.
Of course, we can add some leeway for that; instead of 8 Mbit/sec,
we can choose 16, allowing for two streams. However, most people who
talk about the birthday paradox don't seem to talk much about the
possibility of three connections landing in the same bucket.
I couldn't offhand find any calculations for it, but simple simulation
showed that it happens depressingly often, so if you want to scale
up to, say, a thousand clients, you can pretty much forget to use
this kind of random hashing. (I mean, if you have to allow for ten
connections in each bucket, shaping to 80 Mbit/sec, where's your smoothness
win again?)
The only good way I can think of to get around this problem is to
have some sort of cooperation from userspace. In particular, if you
run VLC as root (or with the network administrator capability), you can use the
SO_MARK socket option to set the fwmark directly from VLC, and then
use the lower bits of that directly to choose bucket. That way, you
could have VLC keep track of which HTB buckets were in use or not,
and just put each new connection in an unused one, sidestepping the
randomness problems in the birthday paradox entirely. (No, I don't
have running code for this.) Of course, if everybody were on IPv6,
you could use the flow label field for this—the RFC says
load balancers etc. are not allowed to assume any special mathematical
properties of this (20-bit) field, but since you're controlling both
ends of the system (both VLC, setting the flow label, and the tc
part that uses it for flow control) you can probably assume exactly
what you want.
So, with that out of the way, at least in theory, let's go to a
presumably less advanced topic. Up until now, I've mainly been talking
about ways to keep TCP's congestion window up (by avoiding spurious
packet drops, which invariably get the sender's TCP to reduce the
congestion window). However, there's another window that also comes
into play, which is much less magical: The TCP receive window.
When data is received on a TCP socket, it's put into a kernel-side
buffer until the application is ready to pick it up (through recv()
or read()). Every ACK
packet contains an updated status of the amount of free space in
the receive buffer, which is presumably the size of the buffer
(which can change in modern TCP implementations, though) minus the
amount of data the kernel is holding for the application.
If the buffer becomes full, the sender can do nothing but
wait until the receiver says it's ready to get more; if the receiver
at some point announces e.g. 4 kB free buffer space, the sender
can send only 4 kB more and then has to wait. (Note that even if
VLC immediately consumes the entire buffer and thus makes lots of
space, the message that there is more space will still need to traverse the
network before the sender can start to push data again.)
Thus, it's a bit suboptimal, and rather surprising, that VLC frequently lets
there be a lot of data in the socket buffer. The exact circumstances under
which this happens is a bit unclear to me, but the general root of the problem
is that VLC doesn't distinguish between streaming a file from HTTP and streaming
a live video stream over HTTP; in the former case, just reading in your own
tempo is the simplest way to make sure you don't read in boatloads of data
you're not going to play (although you could of course spill it to disk),
but in the second one, you risk that the receive buffer gets so small that
it impairs the TCP performance. Of course, if the total amount of buffering
is big enough, maybe it doesn't matter, but again, remember that the socket buffer
is not as easily emptied as an application-managed buffer—there's a
significant delay in refilling it when you need that.
Fixing this in VLC seems to be hard—I've asked on the mailing list
and the IRC channel, and there seems to be little interest in fixing it
(most of the people originally writing the code seem to be long gone).
There is actually code in there that tries to discover if the HTTP resource
is a stream or not (e.g. by checking if the server identifies itself as “Icecast”
or not; oddly enough, VLC itself is not checked for) and then empty the
buffer immediately, but it is disabled since the rest of the clock
synchronization code in VLC can't handle data coming in at such irregular
rates. Also, Linux' receive buffer autotuning does not seem to handle this
case—I don't really understand exactly how it is supposed to work
(ie. what it reacts to), but it does not seem to react to the buffer
oscillating between almost-full and almost-empty.
Interestingly enough, Flash, as broken as it might be in many other aspects, seems to have
no such problem—it consistently advertises a large, constant (or near-constant)
receive window, indicating that it empties its socket buffer in a timely
fashion. (However, after a few minutes it usually freezes shortly for some unknown
reason, causing the buffer to go full—and then it plays fine from that
point on, with an even larger receive window, since the receive window autotuning
has kicked in.) Thus, maybe you won't really need to care about the problem at all;
it depends on your client. Also, you shouldn't worry overly much about this problem either, as most
of the time, there seems to be sufficient buffer free that it doesn't negatively
impact streaming. More research here would be good, though.
So, there you have it. We need: Either paced TCP in Linux or a more intelligent
way of assigning flows to HTB classes, a VLC client with modified buffering for
streaming, and possibly more aggressive TCP receive window autotuning. And
then, all of this turned on by default and on everybody's machines. =)
Sat, 12 May 2012 - TCP optimization for video streaming
At this year's The Gathering, I was once again
head of Tech:Server, and one of our tasks is to get the video stream
(showing events, talks, and not the least demo competitions) to the inside
and outside.
As I've mentioned earlier, we've been using VLC
as our platform, streaming to both an embedded Flash player and people using
the standalone VLC client. (We have viewers both internally and externally
to the hall; multicast didn't really work properly from day one this year,
so we did everything on unicast, from a machine with a 10 Gbit/sec Intel
NIC. We had more machines/NICs in case we needed more, but we peaked at
“only” about 6 Gbit/sec, so it was fine.)
But once we started streaming demo compos, we started getting reports from
external users that the stream would sometimes skip and be broken up.
With users far away, like in the US, we could handwave it away; TCP works
relatively poorly over long-distance links, mainly since you have no control
over the congestion along the path, and the high round-trip time (RTT) causes
information about packet loss etc. to come back very slowly. (Also, if you
have an ancient TCP stack on either side, you're limited to 64 kB windows,
but that wasn't the problem in this case.) We tried alleviating that with
an external server hosted in France (for lower RTTs, plus having an
alternative packet path), but it could not really explain how a 30/30
user only 30 ms away (even with the same ISP as us!) couldn't watch our
2 Mbit/sec stream.
(At this point, about everybody I've talked to go on some variant of
“but you should have used UDP!”. While UDP undoubtedly has no similar
problem of stream breakdown on congestion, it's also completely out of the
question as the only solution for us, for the simple reason that it's
impossible to get it to most of our end users. The best you can do with Flash
or VLC as the client is RTSP with RTP over UDP, and only a small amount of
NATs will let that pass. It's simply not usable as a general solution.)
To understand what was going on, it's useful to take a slightly deeper
dive and look at what the packet stream really looks like. When presented
with the concept of “video streaming”, the most natural reaction would be to
imagine a pretty smooth, constant packet flow. (Well, that or a YouTube
“buffering” spinner.) However, that's really about
as far from the truth as you could come. I took the time to visualize a
real VLC stream from a gigabit line in Norway to my 20/1 cable line in
Switzerland; slowing it down a lot (40x) so you can see what's going on:
(The visualization is inspired by Carlos Bueno's
Packet Flight videos, but I used none of his
code.)
So, what you can see here is TCP being even burstier than its usual self:
The encoder card outputs a frame for encoding every 1/25th second (or 1/50th for the
highest-quality streams), and after x264 has chewed on the data, TCP immediately sends out all of it
as fast as it possibly can. Getting the packets down to my line's speed of
20 Mbit/sec is regarded as someone else's problem (you can see it really does happen,
though, as the packets arrive more spaced out at the other end); and the device
doing it has to pretty much buffer up the entire burst. At TG, this was
even worse, of course, since we were sending at 10 Gbit/sec speeds,
with TSO so that you could get lots of packets out back-to-back at
line rates. To top it off, encoded video is inherently highly bursty
on the micro scale; a keyframe is easily twenty times the size of a B frame,
if not more. (B frames also present the complication that they can't be
encoded until the next one has been encoded, but I'll ignore that here.)
Why are high-speed bursts bad? Well, the answer really has to do with
router buffering along the way. When you're sending such a huge burst
and the router can't send it on right away (ie., it's downconverting
to a lower speed, either because the output interface is only e.g. 1 Gbit/sec, or
because it's enforcing the customer's maximum speed), you stand a risk
of the router running out of buffer space and dropping the packet.
If so, you need to wait at least one RTT for the retransmit; let's just
hope you have selective ACK in your TCP stack, so the rest of the traffic can
flow smoothly in the meantime.
Even worse, maybe your router is not dropping packets when it's
overloaded, but instead keeps buffering them up. This is in many ways even
worse, because now your RTT increases, and as we already discussed,
high RTT is bad for TCP. Packet loss happens whether you want to or
not (not just due to congestion—for instance, my iwl3945 card
goes on a scan through the available 802.11 channels every 120 seconds
to see if there are any better APs on other channels), and when they
inevitably happen, you're pretty much hosed and eventually your stream
will go south. This is known as bufferbloat, and I was really
surprised to see it in play here—I had connected it only to
uploading before (in particular, BitTorrent), but modern TCP supports
continuous RTT measurement through timestamps, and some of the TCP
traces (we took tcpdumps for a few hours during the most intensive
period) unmistakably show the RTT increasing by several hundred
milliseconds at times.
So, now that we've established that big bursts are at least part
of the problem, there are two obvious ways to mitigate the problem:
Reduce the size of the bursts, or make them smoother (less bursty).
I guess you can look at the two as the macroscopic and microscopic
solution, respectively.
As for the first part, we noticed after a while that what really
seemed to give people problems, was when we'd shown a static slide
for a while and then faded to live action; a lot of people would
invariably report problems when that happened. This was
a clear sign that we could do something on the macrocopic level;
most likely, the encoder had saved up a lot of bits while encoding
the simple, static image, and now was ready to blow away its savings
all at once in that fade.
And sure enough, tuning the VBV settings so that the bitrate budget was
calculated over one second instead of whatever was the default (I still don't
know what the default behavior of x264 under VLC is) made an immediate
difference. Things were not really good, but it pretty much fixed the
issue with fades, and in general people seemed happier.
As for the micro-behavior, this seems to be pretty hard to actually fix;
there is something called “paced TCP” with several papers, but nothing in the mainline kernel.
(TCP Hybla is supposed to do this, but the mainline kernel doesn't have the
pacing part. I haven't tried the external patch yet.) I tried implementing
pacing directly within VLC by just sending slowly, and this made the traffic
a lot smoother... until we needed to retransmit, in which case the TCP stack
doesn't care how smoothly data came in in the first place, it justs bursts
like crazy again. So, lose. We even tried replacing one 1x10gigE link with
8x1gigE links, using a Cisco 4948E to at least smooth things down to gigabit
rates, but it didn't really seem to help much.
During all of this, I had going a thread on the bufferbloat mailing list
(with several helpful people—thanks!), and it was from there the second
breakthrough came, more or less in the last hour: Dave Täht suggested that we
could reduce the amount of memory given to TCP for write buffering,
instead of increasing it like one would normally do for higher throughput.
(We did this by changing the global flag in /proc/sys; one could also use
the SO_SNDBUF socket option.) Amazingly enough, this helped a lot! We only
dared to do it on one of the alternative streaming servers (in hindsight this was
the wrong decision, but we were streaming to hundreds of people at the time
and we didn't really dare messing it up too much for those it did work for),
and it really only caps the maximum burst size, but that seemed to push us just
over the edge to working well for most people. It's a suboptimal solution in
many ways, though; for instance, if you send a full buffer (say, 150 kB
or whatever) and the first packet gets lost, your connection is essentially
frozen until the retransmit comes and the ack comes back. Furthermore, it
doesn't really solve the problem of the burstiness itself—it solves
it more on a macro level again (or maybe mid-level if you really want to).
In any case, it was good enough for us to let it stay as it was, and the
rest of the party went pretty smoothly, save for some odd VLC bugs here and
there. The story doesn't really end there, though—in fact, it's still being
written, and there will be a follow-up piece in not too long about post-TG
developments and improvements. For now, though, you can take a look at the
following teaser, which is what the packet flow from my VLC looks like today:
Sat, 14 Jan 2012 - The art of streaming from a demoparty
As 2011 just has come to a close, it's pretty safe to say that video distribution
over the Internet is not the unreliable, exotic mess it was ten years ago.
Correspondingly, more and more demoparties (and other events, which I won't
cover) want to stream their democompo showings to the outside world.
Since I've seen some questions, notably on Pouët's BBS,
I thought I could share some of my own experiences with the subject.
Note that almost all of my own experience comes from The Gathering (TG),
which have been streaming video internally since at least 1999 and externally
since 2003; information about other parties is based on hearsay and/or
guesswork from my own observations, so it might be wrong. Let me know if
there are any corrections.
With that in mind, we jump onto the different pieces that need to fit together!
Your ambition level
First of all, you need to determine how important video streaming really is
for you. Unless you have a huge party, any streaming is going to be irrelevant
for the people inside the hall (who are, after all, your paying visitors);
it might have a PR effect externally, but all in all you probably want to
make sure you have e.g. adequate sleeping space before you start worrying
about streaming.
This is the single most important point of all that I have to say: Make sure
that your ambitions and your expected resource usage are in line. TG has
sky-high ambitions (going much broader than just streaming compos), but backs
that up with a TV production crew of 36 people, a compo crew of thirteen, and
two dedicated encoding people rotating through the day and night to make sure
the streaming itself works. Obviously, for a party with 120 visitors, this
would make no sense at all.
Relevant data point: Most parties don't stream their compos.
The input signal
Getting the signal in digital form, and getting a good one, is not necessarily
easy.
First of all, think of what platforms you are going to stream from.
Older ones might be very easy or very hard; e.g. the C64 has a not-quite-50Hz
signal (it's timed to power) with not-quite-576i (it inserts a fake extra
line in every other field to get a sort-of 288p50 display), which tends to
confuse a lot of video equipment. Modern PC is somewhat better; most demos,
however, will want to change video resolution and/or refresh rate on startup,
which can give you problems to no end.
The ultra-lowtech solution is simply to put a video camera on a tripod and
point it at the big screen. This will give a poor picture, and probably also poor
sound (unless you can get a tap from your sound system), but remember what
I said about ambition. Maybe it's good enough.
Larger parties will tend to already have some kind of video production
pipeline, in which case you can just tap that. E.g., TG uses an HD-SDI setup
with a production bus where most of the pipeline is native, uncompressed
720p50; Revision uses something similar in 1080p based on DVI. Also,
a video mixer will allow you to fade between the compo machine
and one showing the information slide without ugly blinking and stuff.
Such pipelines tend to include scan converters in one form or the other;
if you can get your hands on one, it will make your life much easier. They
tend to take in whatever (VGA/HDMI/composite) and convert it nicely to
one resolution in one connector (although refresh rates could still be
a problem).
At TG, we use the Blackmagic cards;
although their drivers are proprietary, they're pretty cheap, easy to get
to work under Linux (as we used), and the API is a joy to use, although
it descends from COM. The documentation is great, too, so it was easy to
cobble together a VLC driver in a few nights (now part of VLC mainline).
The cheaper alternative is probably DV. Many video cameras will output DV,
and finding a machine with a Firewire input is usually not hard. The quality
is acceptable, typically 576i50 with 4:2:0 subsampling (we did this at TG
for many years). The largest problem with DV is probably that it is interlaced,
which means you'll need to deinterlace either on the server or on the client
(the latter is only really feasible if you use VLC). For most people, this
means cutting the framerate in half to 25fps, which is suboptimal for demos.
(All of this also goes for analogue inputs like S-video or composite,
except those also have more noise. Don't confuse composite with component,
though; the former is the worst you can get, and the latter is quite good.)
The software
The base rule when it comes to software is: There is more than one way to do it.
Revision uses Adobe's Flash suite; it's expensive, but maybe you can get a
sponsored deal if you know someone. The cheaper version of this is
Wowza; it gives you sort-of the same thing
(streaming to Flash), just a lot cheaper. At least Assembly uses Wowza
(and my guess is also TUM and several other parties); TG used to, but
we don't anymore.
TG has been through a lot of solutions: Cisco's MPEG-1-based stuff in 1999,
Windows Media streaming from 2003, Wowza some years, and VLC
exclusively the last few ones. VLC has served us well; it allows us to
run without any Windows in the mix (a win or a loss, depending on who
you ask, I guess), very flexible, totally free, and it allows streaming to
Flash.
Generally, you probably just want to find whatever you have the most
experience with, and run with that.
The encoder
The only codec you realistically want for video distribution these days
is H.264; however, there's huge variability between the different codecs
out there. Unfortunately, you are pretty much bound by whatever software
you chose in the previous step.
Encoding demos is not like encoding movies. Demos has huge amounts of hard
edges and other high-frequency content, lots of rapid and unpredictable
movement, noise, and frequent flashing and scene changes. (Also remember that
there is extra noise if your input signal is analogue; even a quite high-end DV
cam will make tons of noise in the dark!) This puts strains on the video
encoder in a way quite unlike most other content. Add to ths the fact that you
probably want to stream in 50p if you can (as opposed to 24p for most movies),
and it gets really hard.
In my quite unscientific survey (read: I've looked at streams from various
parties), Wowza's encoder is really poor; you don't really need a lot of
action on the screen before the entire picture turns to blocky mush. (I'm not
usually very picky about these things, FWIW.) The Adobe suite is OK;
x264 (which VLC uses) is really quite clearly the best, although it wants your CPU for lunch
if you're willing to give it that. Hardware H.264 encoders are typically about
in the middle of the pack—“hardware” and “expensive” does not automatically mean “good”,
even though it's easy to be wooed by the fact that it's a shiny box that
can't do anything else. It's usually a pretty stable bet, though,
if you can get it working with your pipeline and clients in the first place.
There are usually some encoder settings—first of all, bitrate. 500 kbit/sec
seems to be the universal lowest common denominator for video streams, but
you'll want a lot more for full 576p or 720p. (More on this below.) You can
also usually select some sort of quality preset—just use the most expensive
you can go without skipping frames. At TG, this typically means “fast”
or “veryfast” in VLC, even though we have had quite beefy quad- or octocores.
Also, remember that you don't really care much about latency, so you can
usually crank up the lookahead to ten seconds or so if it's set lower.
Mantra: The most likely bottleneck is the link out of your hall. The second
most likely bottleneck you will have no control over. (It is the public
Internet.)
Most parties, large and small, have completely clogged outgoing Internet
lines. You will need to plan accordingly. (And even if MRTG shows your line
is not clogged, TCP works in mysterious ways when traversing congested links.)
By far the easiest tactic is to
get one good stream out of the hall, to some external reflector; ask a bit
around, and you can probably get something done at some local university
or get some sponsorship from an ISP.
Getting that single copy out of the hall can also require some thought.
If you have reasonably advanced networking gear, you can probably QoS away
that problem; just prioritize the stream traffic (or shape all the others).
If you can't do that, it's more tricky—if your reflector is really
close to you network-wise, it might “win”, since TCP often fares better with low-latency
streams, but I wouldn't rely on that. You could let them traverse entirely
different links (3G, anyone?), or simply turn off the public Internet
access for your visitors altogether. It's your choice, but don't be
unprepared, because it will happen.
Note that even if you would have spare bandwidth out of your site (or if you
can get it safely to some other place where the tubes are less crowded), this
doesn't mean you can just crank up the bitrate as you wish. The public Internet
is a wonderful but weird place, and even if most people have multi-deca-megabit
Internet lines at home these days, that doesn't mean you can necessarily haul a
2 Mbit/sec TCP stream stably across the continent. (I once got a request for a
version of the TG stream that would be stable to a small Internet café in
Cambodia. Ideally in quarter-quarter-screen, please.)
There are two solutions for this: Either use a lowest common denominator,
or support a variety of bandwidths. As mentioned before, the standard
seems to be 360p or so in about 500 kbit/sec, where 64 kbit/sec of those are used for
AAC audio. (Breakpoint used to change the bitrate allocation during
music compos to get high-quality audio, but I don't know if Revision has
carried this forward.) For high-quality 720p50, you probably want something
like 8 Mbit/sec. And then you probably want something in-between those two,
e.g. 576p50 (if you can get that) at 2 Mbit/sec.
(I can't offhand recall anyone who streams in 1080p, and probably for good
reason; it's twice the bandwidth and encoding/decoder power without an obvious
gain in quality, as few demos run in 1080p to begin with.)
Ideally you'd want some sort of CDN for this. The “full-scale” solution
would be something like Akamai, but that's probably too expensive for a
typical demoparty. (Also, I have no idea how it works technically.)
Gaming streams, typically with a lot more visitors
(tens of thousands for the big competitions), are typically done using
uStream or Justin.tv,
but I've never seen a demoparty use those (except for when we used a laptop's
webcam during Solskogen once)—the picture quality is pretty poor stuff,
and even though they will work about equally for 10 and 10000 viewers,
that doesn't really mean they work all that well for 10 always.
In short, the common solution is to not use a CDN, and just have a single
reflection point, but usually outside the hall.
The player
The standard player these days is Flash.
I'm personally not a big fan of Flash; the plug-in is annoying,
it necessitates Flashblock or Adblock if you want to surf the web without
killing your battery, and it's generally unstable. (Also, it can't
deinterlace, so you'd need to do that on the server if your stream
is interlaced, so worse quality.) But for video distribution
on the web, having a Flash client will give you excellent coverage, and these
days, the H.264 decoder isn't all that slow either.
Adobe's own media suite and Wowza will stream to Flash natively; VLC will
with some light coaxing. I don't think Windows Media will do, though;
you'd need Silverlight, which would make a lot more people pretty mad at
you (even though it's getting more and more popular for commercial live TV
distribution, maybe for DRM reasons).
There's nothing saying you can't have multiple players if you want to make
people happy, though. In some forms (HTTP streaming), the VLC client can
play Flash streams; in others (RTMP), it's a lot harder. I doubt many
play demoparty streams from set-top boxes or consoles, but a separate player
is generally more comfortable to work with once you need to do something
special, e.g. stream to your ARM-based HTPC, do special routing with the
audio, or whatnot.
One thing we've noticed is that bigger is not always better; some people
would just like a smaller-resolution stream so they can do other things
(code, surf, IRC, whatever) while they keep the stream in a corner.
One thing you can do to accomodate this is to make a separate pop-up player
this has very low cost but huge gains, since people are free to move the
player around as they wish, unencumbered by whatever margins you thought
would be aesthetically pleasing on the main page. Please do this;
you'll make me happy. :-)
If you have other formats (e.g. VLC-friendly streaming) or other streams
(e.g. HD), please link to them in a visible place from the stream player.
It's no fun having to navigate several levels of well-hidden links to try to
find the RTSP streams. (I'm looking at you, Assembly.)
Final words
This section contains the really important stuff, which is why I put it
at the end so you've gotten bored and stopped reading a while ago.
I already said that the most important advice I have to give is to align
your ambition level and resources you put into the stream, but the second
most is to test things beforehand. My general rule of thumb is that
you should test early enough that you have time to implement a different
solution if the test fails; otherwise, what good would testing be?
(Of course, if “no stream” would be an acceptable plan B, you can test
five minutes before, but remember that you'll probably make people more
unhappy than if you never announced a stream in the first place, then.)
There's always bound to be something you've forgotten; if you test the
day before, you'll be able to get someone to get that single €5 cable
that would save the day, but you probably won't be able to fix
“the video mixer doesn't like the signal from the C64, we need to get
a new one”. In general, you want to test things as realistically as
possible, though; ideally with real viewers as well.
Finally, have contact information on your page. There are so many
times I've seen things that are really easy to fix, but nowhere to
report them. Unless you actually monitor your own stream, it's really
easy to miss clipped audio, a camera out of focus, or whatnot.
At the very least, include an email address; you probably also want
something slightly more real-time if you can (e.g. IRC). Also, if there
is a Pouët thread about your party, you should probably monitor it,
since people are likely to talk about your stream there.
And now, for the final trick: No matter if you have or don't have
a video stream, you should consider inviting SceneSat.
You'll need to ensure stable delivery of their stream out of the hall
(see the section on QoS :-) ), but it gives you a nice radio stream
capturing the spirit of your party in an excellent way, with an existing
listener base and minimal costs for yourself. If you don't have a video
stream, you might even get Ziphoid to narrate your democompo ;-)
This time there is no new material, only a few comments from readers of
the series of the last few days. Thanks; you know who you are.
The UDP output is not the only VLC output that can multicast; in particular,
the RTP mux/output can do it, too, in which case the audio and video streams
are just sent out more or less as separate streams. This would avoid any
problems the TS mux might have, and probably replace them with a whole new
and much more interesting set. (I've never ever had any significant success
with RTP as a user, so I don't think I'll dare to unleash it from the server
side. In any case we need TS for the HTTP streams, and sticking with fewer
sets of options is less confusing if we can get away with it.)
VLC 1.1.x can reportedly use H.264 decoding hardware if your
machine, OS and drivers all support that. I have no idea how it impacts latency
(it could go both ways, I reckon), but presumably it should at least make
decoding on the client side cheaper in terms of CPU.
If you're running slice-based threads, you might not want to use too many
threads, or bitrate allocation might be very inefficient.
The DVD LPCM encoder is now in VLC's git repository. Yay :-)
The collective bag of hacks I use that have not been sent upstream can
be found here.
Caveat emptor.
Finally, I realized I hadn't actually posted our current command-line anywhere,
so here goes:
You'll probably want to up the bitrate for a real stream. A lot. And of course, coding PAL
as non-interlaced doesn't make much sense either, unless it happens to be a progressive
signal sent as interlaced.
I'll keep you posted if there's any new movement (new latency tests, more patches
going into VLC, or similar), but for now, that's it. Enjoy :-)
In previous parts, I've been talking about the motivations for our
low-latency VLC setup, the overall plan, codec latency
and finally timing. At this point we're going down into more
specific parts of VLC, in an effort to chop away the latency.
So, when we left the story the last time, we had a measured 1.2 seconds of
latency. Obviously there's a huge source of latency we've missed somewhere,
but where?
At this point I did what I guess most others would have done; invoked VLC with
--help and looked for interesting flags. There's a first obvious
candidate, namely --sout-udp-caching, which is yet another
buffering flag, but this time on the output part of the side. (It seems to
delay the DTS, ie. the sending time delay in this case, by that many
milliseconds, so it's a sender-side equivalent of the PTS delay.) Its default,
just like the other “-caching” options, is 300 ms. Set it down to 5 ms (later
1 ms), and whoosh, there goes some delay. (There's also a flag called
“DTS delay” which seems to adjust the PCR relative to the DTS, to give the
client some more chance at buffering. I have no idea why the client would
need the encoder to specify this.)
But there's still lots of delay left, and with some help from the people on
#x264dev (it seems like many of the VLC developers hang there, and it's a lot
less noisy than #videolan :-) ) I found the elusively-named flag
--sout-ts-shaping, which belongs to the TS muxer module.
To understand what this parameter (the “length of the shaping interval, in
milliseconds”) is about, we'll need to take a short look at what a muxer does.
Obviously it does the opposite of a demuxer — take in audio and video,
and combine them into a finished bitstream. It's imperative at this point that
they are in the same time base, of course; if you include video from
00:00:00 and audio from 00:00:15 next to each other, you can be pretty
sure there's a player out there that will have problems playing your audio
and video in sync. (Not to mention you get fifteen seconds delay, of course.)
VLC's TS muxer (and muxing system in general) does this by letting the audio
and video threads post to separate FIFOs, which the muxer can read from.
(There's a locking issue in here in that the audio and video encoding seem
to take the same lock before posting to these FIFOs, so they cannot go in
parallel, but in our case the audio decoding is nearly free anyway, so it
doesn't matter. You can add separate transcoder threads if you want
to, but in that case, the video goes via a ring buffer that is only polled
when the next frame comes, so you add about half a frame of extra delay.)
The muxer then is alerted whenever there's new stuff added to any of the FIFOs,
and sees if it can output a packet.
Now, I've been told that VLC's TS muxer is a bit suboptimal in many aspect,
and that there's a new one that has been living out-of-tree for
a while, but this is roughly how the current one works:
Pick one stream as the PCR stream (PCR is MPEG-speak for “Program Clock
Reference”, the global system clock for that stream), and read blocks
of total length equivalent to the shaping period. VLC's TS muxer tries to
pick the video stream as the PCR stream if one exists. (Actually, VLC waits
a bit at the beginning to give all streams a chance to start sending data,
which identifies the stream. That's what the --sout-mux-caching
flag is for. For us, it doesn't matter too much, though, since what we
care about is the steady state.)
Read data from the other streams until they all have at least caught up with
the PCR stream.
From #1 it's pretty obvious that the default shaping interval of 200 ms is
going to delay our stream by several frames. Setting it down to 1, the lowest
possible value, again chops off some delay.
At this point, I started adding printfs to see how the muxer worked, and it
seemed to be behaving relatively well; it picked video blocks (one frame,
40 ms), and then a bunch of audio blocks (the audio is chopped into 80-sample
blocks by the LPCM encoder, in addition to a 1024-sample chop at some
earlier point I don't know the rationale for). However, sometimes it would
be an audio block short, and refuse to mux until it got more data (read:
the next frame). More debugging ensued.
At this point, I take some narrative pain for having presented the story
a bit out-of-order; it was actually first at this point I added the SDI timer
as the master clock. The audio and video having different time bases would
cause problems where the audio would be moved, say, 2ms more ahead than the
video. Sorry, you don't have enough video to mux, wait for more. Do not collect
$500. (Obviously, locking the audio and video timestamps fixed this specific
issue.) Similarly, I found and fixed a few rounding issues in the length
calculations in the LPCM encoder that I've already talked briefly about.
But there's more subtility, and we've touched on it before. How do you find
the length of a block? The TS muxer doesn't trust the length parameter from
previous rounds, and perhaps with good reason; the time base correction could
have moved the DTS and PTS around, which certainly should also skew the
length of the previous block. Think about it; if you have a video frame at
PTS=0.000 and then one at PTS=0.020, and the second frame gets moved to
to PTS=0.015, the first one should obviously have length 0.015, not 0.020.
However, it may already have been sent out, so you have a problem. (You could
of course argue that you don't have a problem, since your muxing algorithm
shouldn't necessarily care about the lengths at all, and the new TS muxer
reportedly does not. However, this is the status quo, so we have to care about
the length for now. :-) )
The TS muxer solves this in a way that works fine if you don't care about
latency; it never processes a block until it also has the next block.
By doing this, it can simply say that this_block.length = next_block.dts -
this_block.dts, and simply ignore the incoming length parameter of the block.
This makes for chaos for our purposes, of course -- it means we will always
have at least one video frame of delay in the mux, and if for some reason
the video should be ahead of the audio (we'll see quite soon that it usually
was!), the muxer will refuse to mux the packet on time because it doesn't
trust the length of the last audio block.
I don't have a good upstream fix for this, except that again, this is supposedly
fixed in the new muxer. In my particular case, I did a local hack and simply
made the muxer trust the incoming length -- I know it's good anyway. (Also,
of course, I could then remove the demand that there be at least two blocks
left in the FIFO to fetch out the first one.)
But even after this hack, there was a problem that I'd been seeing throughout
the entire testing, but never really understood; the audio was consistently
coming much later than the video. This doesn't make sense, of course, given
that the video goes through x264, which takes a lot of CPU time, and the audio
is just chopped into blocks and given DVD LPCM headers. My guess was at some
serialization throughout the pipeline (and I did indeed find one, the serialized
access to the FIFOs mentioned earlier, but it was not the right source),
and I started searching. Again lots of debug printfs, but this time, at least
I had pretty consistent time bases throughout the entire pipeline, and only
two to care about. (That, and I drew a diagram of all the different parts of
the code; again, it turns out there's a lot of complexity that's basically
short-circuited since we work with raw audio/video in the input.)
The source of this phenomenon was finally found in a place I didn't even
know existed: the “copy packetizer”. It's not actually in my drawing, but
it appears it sits between the raw audio decoder (indeed…) and the LPCM
encoder. It seems mostly to be a dummy module because VLC needs there to
actually be a packetizer, but it does do some sanity checking and adjusts
the PTS, DTS and... length. Guess how it finds the new length. :-)
For those not following along: It waits for the next packet to arrive, and
sets the new length equivalent to next_dts - this_dts, just like ths TS
muxer. Obviously this means one block latency, which means that the TS
muxer will always be one audio block short when trying to mux the video
frame that just came in. (The video goes through no similar treatment along
its path to the mux.) This, in turn, translates to a minimum latency of
one full video frame in the mux.
So, again a local hack: I have no idea what downstream modules may rely on
the length being correct, but in my case, I know it's correct, so I can
just remove this logic and send the packet directly on.
And now, for perhaps some disappointing news: This is the point where the
posting catches up with what I've actually done. How much latency is there?
I don't know, but if I set x264 to “ultrafast” and add some printfs here
and there, it seems like I can start sending out UDP packets about 4 ms
after receiving the frame from the driver. What does this translate to in
end-to-end latency? I don't know, but the best tests we had before the
fixes mentioned (the SDI master clock, the TS mux one-block delay, and the copy
packetizer one-block delay) was about 250 ms:
That's a machine that plays its own stream from the local network, so
intrinsically about 50 ms better than our previous test, but the difference
between 1.2 seconds and 250 ms is obviously quite a lot nevertheless.
My guess is that with these fixes, we'll touch about 200 ms, and then when
we go to true 50p (so we actually get 50 frames per second, as opposed to 25
frames which each represent two fields), we'll about halve that. Encoding
720p50 in some reasonable quality is going to take some serious oomph, though,
but that's really out of our hands — I trust the x264 guys to keep doing
their magic much better than I can.
So, I guess that rounds off the series; all that's left for me to write at
the current stage is a list of the corrections I've received, which I'll do
tomorrow. (I'm sure there will be new ones to this part :-) )
What's left for the future? Well, obviously I want to do a new end-to-end
test, which I'll do as soon as I have the opportunity. Then I'm quite sure
we'll want to run an actual test at 720p50, and for that I think I'll need
to actually get hold of one of these cards myself (including a desktop machine
fast enough to drive it). Hello Blackmagic, if you by any chance are throwing
free cards at people, I'd love one that does HDMI in to test with :-P
Of course, I'm sure this will uncover new issues; in particular, we haven't
looked much at the client yet, and there might be lurking unexpected delays
there as well.
And then, of course, we'll see how it works in practice at TG. My guess is
that we'll hit lots of weird issues with clients doing stupid things — with
5000 people in the hall, you're bound to have someone with buggy audio or video
drivers (supposedly audio is usually the worst sinner here), machines with
timers that jump around like pinballs, old versions of VLC despite big warnings
that you need at least X.Y.Z, etc… Only time will tell, and I'm pretty glad
we'll have a less fancy fallback stream. :-)
Previously in my post on our attempt at a low-latency VLC setup for The
Gathering 2011, I've written about motivation, the
overall plan and yesterday on codec latency. Today we'll
look at the topic of timestamps and timing, a part most people probably think
relatively little about, but which is still central to any sort of audio/video
work. (It is also probably the last general exposition in the series; we're
running out of relevant wide-ranging topics to talk about, at least of the
things I pretend to know anything about.)
Timing is surprisingly difficult to get right; in fact, I'd be willing to bet
that more hair has been ripped out over the supposedly mundane issues of
demuxing and timestamping than most other issues in creating a working
media player. (Of course, never having made one, that's just a guess.)
The main source of complexity can be expressed through this quote
(usually attributed to a “Lee Segall” who I have no idea who is):
“A man with a watch knows what time it is. A man with two watches is never sure.”
In a multimedia pipeline, we have not only two but several different clocks
to deal with: The audio and video streams both have clocks, the kernel has its
own clock (usually again based on several different clocks, but you don't
need to care much about that), the client in the other end has a kernel clock,
and the video and audio cards for playback both have clocks. Unless they are
somehow derived from exactly the same clock, all of these can have different
bases, move at different rates, and drift out of sync from each other.
That's of course assuming they are all stable and don't do weird things like
suddenly jump backwards five hours and then back again (or not).
VLC, as a generalist application, generally uses the only reasonable general
approach, which is to try to convert all of them into a single master timer,
which comes from the kernel. (There are better specialist approaches in some
cases; for instance, if you're transcoding from one file to another, you
don't care about the kernel's idea of time, and perhaps you should choose one
of the input streams' timestamps as the master instead.)
This happens separately for audio and video, in our case right before it's sent
to the transcoder — VLC takes a system timestamp, compares it to the stream
timer, and then tries to figure out how the stream timer and the system
relates, so it can convert from one to the other. (The observant reader, which
unfortunately never has existed, will notice that it should have taken this
timestamp when it actually received the frame, not the point where it's about
to encode it. There's a TODO about this in the source code.) As the relations
might change over time, it tries to slowly adjust the bases and rates to
match reality. (Of course, this is rapidly getting into control theory,
but I don't think you need to go there to get something that works reasonably
well.) Similarly, if audio and video go too much out of sync, the VLC client
will actually start to stretch audio one way or the other to get the two
clocks back in sync without having to drop frames. (Or so I think. I don't
know the details very well.)
But wait, there's more. All data blocks have two timestamps, the presentation
timestamp (PTS) and the decode timestamp (DTS). (This is not a VLC invention
by any means, of course.) You can interpret both as deadlines; the PTS is
a deadline for when you are to display the block, and the DTS is a deadline
for when the block is to be decoded. (For streaming over the network, you
can interpret “display” and “decode” figuratively; the UDP output, for instance,
tries to send out the block before the DTS has arrived.) For a stream, generally
PTS=DTS except when you need to decode frames out-of-order (think B-frames).
Inside VLC after the time has been converted to the global base, there's a
concept of “PTS delay”, which despite the name is added to both PTS and DTS.
Without a PTS delay, the deadline would be equivalent to the stream acquisition
time, so all the packets would be sent out too late, and if you had the
--sout-transcode-hurry-up (which is default) the frames would
simply get dropped. Again confusingly, the PTS delay is set by the various
--*-caching options, so basically you want to set
--decklink-caching as low as you can without warnings about
“packet sent out too late” showing up en masse.
Finally, all blocks in VLC have a concept of length, in milliseconds. This
sounds like an obvious choice until you realize all lengths might not be
a whole multiple of milliseconds; for instance, the LPCM blocks are 80 samples
long, which is 5/3 ms (about 1.667 ms). Thus, you need to set rounding right
if you want all the lengths to add up — there are functions to help with this
if your timestamps can be expressed as rationals numbers. And of course, since consecutive
blocks might get converted to system time using different parameters,
pts2 - pts1 might very well be different from length. (Otherwise, you
could never ever adjust a stream base.) And to make things
even more confusing, the length parameter is described as optional for some
types of blocks, but only in some parts of the VLC code. You can imagine
latency problems being pretty difficult to debug in an environment like this,
with several different time bases in use from different threads at the same
time.
But again, our problem at hand is simpler than this, and with some luck,
we can short-circuit away much of the complexity we don't need. To begin
with, SDI has locked audio and video; at 50 fps, you always get exactly
20 ms of audio (960 samples at 48000 Hz) with every video frame. So we
don't have to worry about audio and video going out of sync, as long as VLC
doesn't do too different things to the two.
This is not necessarily a correct assumption — for instance, remember that VLC
can sample the system timer for the the audio and video at different times and
in different threads, so even though they originally have the same timestamp
from the card, VLC can think they have different time bases, and adjust the
time for the audio and video blocks differently. They start as locked, but VLC
does not process them as such, and once they drift even a little out of sync,
things get a lot harder.
Thus, I eventually found out that the easiest thing for me was to take the
kernel timer out of the loop. The Blackmagic cards give you access to the
SDI system timer, which is locked to the audio and video timers. You only
get the audio and video timestamps when you receive a new frame, but you can
query the SDI system timer at any time, just like the kernel timer. You
can also ask it how far you are into the current frame, so if you just
subtract that, you will get a reliable timestamp for the acquisition of
the previous frame, assuming you haven't been so busy you skipped an entire
frame, in which you case you lose anyway.
The SDI timer's resolution is only 4 ms, it seems, but that's enough for us — also, even
though its rate is 1:1 to the other timers, its base is not the same, so
there's a fixed offset. However, VLC can already deal with situations like
this, as we've seen earlier; as long as the base never changes, it will be
right from first block, and there will never be any drift. I wrote a patch
to a) propagate the actual frame acquisition time to the clock correction
code (so it's timestamped only once, and the audio and video streams will
get the same system timestamps), and b) make VLC's timer functions fetch the
SDI system timer from the card instead of from the kernel. I don't know if
the last part was actually necessary, but it certainly made debugging/logging
a lot easier for me. One True Time Base, hooray. (The patch is not sent
upstream yet; I don't know if it would be realistically accepted or not,
and it requires more cleanup anyhow.)
So, now our time bases are in sync. Wonder how much delay we have? The
easiest thing is of course to run a practical test, timestamping things
on input and looking what happens at the output. By “timestamping”, I
mean in the easiest possible way; just let the video stream capture a clock,
and compare the output with another (in sync) clock. Of course, this means
your two clocks need to be either the same or in sync — and for the first
test, my laptop suddenly plain refused to sync properly to NTP with more
than 50 ms or so. Still, we did the test, with about 50 ms network latency,
with a PC running a simple clock program to generate the video stream:
(Note, for extra bonus, that I didn't think of taking a screenshot instead
of a photo. :-) )
You'll see that despite tuning codec delay, despite turning down the PTS
delay, and despite having SDI all the way in the input stream, we have a delay
of a whopping 1.2 seconds. Disheartening, no? Granted, it's at 25 fps (50i)
and not 50 fps, so all frames take twice as long, but even after a theoretical
halving (which is unrealistic), we're a far cry from the 80 ms we wanted.
However, with that little cliffhanger, our initial discussion of timing is
done. (Insert lame joke about “blog time base” or similar here.)
We'll look at tracing the source(s) of this unexpected amount of latency
tomorrow, when we look at what happens when the audio and video streams are
to go back into one, and what that means for the pipeline's latency.
Thu, 07 Oct 2010 - VLC latency, part 3: Codec latency
In previous parts, I wrote a bit about motivation and
overall plan for our attempt at a low-latency VLC setup.
Today we've come to our first specific source of latency, namely
codec latency.
We're going to discuss VLC streaming architecture in more detail later on, but
for now we can live with the (over)simplified idea that the data comes in from
some demuxer which separates audio and video, then audio and video are
decoded and encoded to their new formats in separate threads, and finally
a mux combines the newly encoded audio and video into a single bit stream
again, which is sent out to the client.
In our case, there are a few givens: The Blackmagic SDI driver actually takes
on the role as a demuxer (even though a demuxer normally works on some
bitstream on disk or from network), and we have to use the TS muxer (MPEG
Transport Stream, a very common choice) because that's the only thing that
works with UDP output, which we need because we are to use multicast.
Also, in our case, the “decoders” are pretty simple, given that the driver
outputs raw (PCM) audio and video.
So, there are really only two choices to be made, namely the audio and video
codec. These were also the first places where I started to attack latency,
given that they were the most visible pieces of the puzzle (although not
necessarily the ones with the most latency).
For video, x264 is a pretty obvious choice these days, at least
in the free software world, and in fact, what originally inspired the project
was this blog post on x264's newfound support for various low-latency
features. (You should probably go read it if you're interested; I'm not going
to repeat what's said there, given that the x264 people can explain their
own encoder a lot better than I can.)
Now, in hindsight I realized that most of these are not really all that
important to us, given that we can live with somewhat unstable bandwidth
use. Still, I wanted to try out at least Periodic Intra Refresh in practice,
and some of the other ones looked quite interesting as well.
VLC gives you quite a lot of control over the flags sent to x264; it used
to be really cumbersome to control given that VLC had its own set of defaults
that was wildly different from x264's own defaults, but these days it's
pretty simple: VLC simply leaves x264's defaults alone in almost all cases
unless you explicitly override them yourself, and apart from that lets you
specify one of x264's speed/quality presets (from “ultrafast” down to
“placebo”) plus tunings (we use the “zerolatency” and “film” tunings together,
as they don't conflict and both are relevant to us).
At this point we've already killed a few frames of latency — in particular,
we no longer use B-frames, which by definition requires us to buffer at least
one frame, and the “zerolatency” preset enables slice-based threading,
which uses all eight CPUs to encode the same frame instead of encoding eight
frames at a time (one on each CPU, with some fancy system for sending the
required data back and forth between the processes as it's needed for
inter-frame compression). Reading about the latter suddenly made me understand
why we always got more problems with “video buffer late for mux” (aka:
the video encoder isn't delivering frames fast enough to the mux) when we
enabled more CPUs in the past :-)
However, we still had unexpectedly much latency, and some debug printfs
(never underestimate debug printfs!) indicated that VLC was sending five
full frames to x264 before anything came out in the other end. I digged through
VLC's x264 encoder module with some help from the people at #x264dev, and
lo and behold, there was a single parameter VLC didn't keep at default,
namely the “lookahead” parameter, which was set to... five. (Lookahead is
useful to know whether you should spend many or fewer bits on the current
frame, but in our case we cannot afford that luxury. In any case, the x264
people pointed out that five is a completely useless number to use; either you
have lookahead of several seconds or you just drop the concept entirely.)
--sout-x264-lookahead 0 and voila, that problem disappeared.
Periodic Intra Refresh (PIR), however, was another story. It's easily enabled
with --sout-x264-intra-refresh (which also forces a few other
options currently, such as --sout-x264-ref 1, ie. use reference
pictures at most one frame back; most of these are not conceptual limitations,
though, just an effect of the current x264 implementation), but it causes
problems for the client. Normally, when the VLC client “tunes in” to a running
stream, it waits until the first key frame before it starts showing anything.
With PIR, you can run for ages with no key frames at all (if there's no clear
scene cut); that's sort of the point of it all. Thus, unless the client
happened to actually see the start of the stream, it could be stuck in a state
where it would be unable to show anything at all. (It should be said that
there was also a server-side shortcoming in VLC here at a time, where it didn't
always mark the right frames as keyframes, but that's also fixed in the 1.1
series.)
So, we have to patch the client. It turns out that the Right Thing(TM) to do
is to parse something called SEI recovery points, which is a small piece of
metadata the encoder inserts whenever it's beginning a new round of its
intra refresh. Essentially this says something like “if you start decoding
here now, in NN frames you will have a correct [or almost correct, if a
given bit it set] picture no matter what you have in your buffer at this
point”. I made a patch which was reviewed and is now in VLC upstream;
there have been some concerns about correctness, though (although none that
cover our specific use-case), so it might unfortunately be reverted at some
point. We'll see how it goes.
Anyhow, now we're down to theoretical sub-frame (<20ms) latency in the
video encoder, so let's talk about audio. It might not be obvious to most
people, but the typical audio codecs we use today (MP3, Vorbis, AAC, etc.)
have quite a bit of latency inherent to the design. For instance, MP3 works
in 576-sample blocks at some point; that's 12ms at 48 kHz, and the real
situation is much worse, since that's within a subband, which has already
been filtered and downsampled. You'll probably find that MP3 latency in
practice is about 150–200 ms or so (IIRC), and AAC is something similar;
in any case, at this point audio and video were noticeably out of sync.
The x264 post mentions CELT as a possible high-quality, low-latency
audio codec. I looked a bit at it, but
VLC doesn't currently support it,
It's not bitstream stable (which means that people will be very reluctant
to distribute anything linked against it, as you can break client/server
compatibility at any time), and
It does not currently have a TS mapping (a specification for how to embed
it into a TS mux; every codec needs such a mapping), and I didn't really
feel like going through the procedure of defining one, getting it
standardized and then implement it in VLC.
I looked through the list of what usable codecs were supported by the
TS demuxer in the client, though, and one caught my eye: LPCM. (The “L”
stands for simply “linear” — it just means regular old PCM for all practical
purposes.) It turns out both DVDs and Blu-rays have support for PCM,
including surround and all, and they have their own ways of chopping the PCM
audio into small blocks that fit neatly into a TS mux. It eats bandwidth,
of course (48 kHz 16-bit stereo is about 1.5 Mbit/sec), but we don't really
need to care too much; one of the privileges of controlling all parts of
the chain is that you know where you can cut the corners and where you cannot.
The decoder was already in place, so all I had to do was to write an encoder.
The DVD LPCM format is dead simple; the decoder was a bit underdocumented,
but it was easy to find more complete specs online and update VLC's comments.
The resulting patch was again sent in to VLC upstream, and is
currently pending review. (Actually I think it's just forgotten, so I should
nag someone into taking it in. It seems to be well received so far.)
With LPCM in use, the audio and video dropped neatly back into sync, and at
this point, we should have effectively zero codec latency except the time spent
on the encoding itself (which should surely be below one frame, given that the
system works in realtime). That means we can start hacking at the rest of
the system; essentially here the hard, tedious part starts, given that we're
venturing into the unknowns of VLC internals.
This also means we're done with part three; tomorrow we'll be talking about
timing and timestamps. It's perhaps a surprising topic, but very important both
in understanding VLC's architecture (or any video player in general), the
difficulties of finding and debugging latency issues, and where we can find
hidden sources of latency.
Yesterday,
I introduced my (ongoing) project to set up a low-latency video stream with
VLC. Today it's time to talk a bit about the overall architecture, and the
signal acquisition.
First of all, some notes on why we're using VLC. As far as I can remember,
we've been using it at TG, either alone or together with other software,
since 2003. It's been serving us well; generally better than the other
software we've used (Windows Media Encoder, Wowza), although not without
problems of its own. (I remember we discovered pretty late one year that
while VLC could encode, play and serve H.264 video correctly at the
time, it couldn't actually reflect it reliably. That caused interesting
headaches when we needed a separate distribution point outside the hall.)
One could argue that writing something ourselves would give more control
(including over latency), but there are a few reasons why I'm reluctant:
Anything related to audio or video tends to have lots of subtle little
issues that are easy to get wrong, even with a DSP education. Not to mention
that even though the overarching architecture looks simple, there's heck
of a lot of small details (when did you last write a TS muxer?).
VLC is excellent as generalist software; I'm wary of removing all the
tiny little options, even though we use few of them. If I suddenly need
to scale the picture down by 80%, or use a different input, I'm hosed
if I've written my own, since that code just isn't there when I need it.
We're going to need VLC for the non-low-latency streams anyhow, so
if we can do with one tool, it's a plus.
Contributing upstream is, generally, better than making yet another
project.
So, we're going to try to run it with VLC first, and then have “write our own”
as not plan B or C, but probably plan F somewhere. With that out of the way,
let's talk about the general latency budget (remember that our overall goal
is 80ms, or four frames at 50fps):
Inputting the frame: 20ms. While SDI is a cut-through
system, there's no way we can get VLC to operate on less than a whole
frame at a time, and the SDI card doesn't support it anyway as far as I
know. (SDI sends the frame at the signal rate, so it really takes one frame
to input one frame.)
H.264 encoding: 10ms. We assume we can encode the frame
at twice the realtime speed in acceptable quality. This probably requires
a relatively fast quad- or octocore.
Network latency: 5ms. Since we're only distributing within
the local network, bandwidth is essentially free, but there's always
going to be some delay in various networking stacks, routers, etc.
anyway, and of course, outputting a megabit of data at gigabit speeds will
take you a millisecond. (A megabit per frame would of course mean 50Mbit/sec
at 50 fps, and we're not going that high, but still.)
H.264 decoding: 10ms. We assume decoding can happen in
twice the realtime speed; of course, decoding is usually a lot faster
than encoding (even though VLC cannot, as far as I know, use H.264 hardware
acceleration at this point); this should give us some leeway for slower
computers.
Client buffering: 20ms. We don't really have all that much
control over the client, and this is sort of a grey area, so it's better
to be prepared for this.
Screen display: 20ms. Again, there might various forms
of buffering in place here, not to mention that you'll need to wait for
vertical sync.
As you can see, a lot of these numbers are based on guesswork. Also, they
sum up to 85ms — slightly more than our 80ms goal, but okay, at least it's
in the right ballpark. We'll see how things pan out later.
This also explains why we need to start so early — not only are there lots
of unknowns, but some of the latency is pretty much bound to be lurking in
the client somewhere. We have full control over the server, but we're not
going to be distributing our own VLC version to the 5000+ potential viewers
(maintaining custom VLC builds for
Windows, OS X and various Linux distributions is not very high on my list),
so it means we need to get things to upstream, and then wait for the code
to find its way to a release and then down onto people's computers in various
forms. (To a degree, we can ask people to upgrade, but it's better if the
right version is just alreayd on their system.)
So, time to get the signal into the system. Earlier we've been converting
the SDI signal to DV, plugged it into a laptop over Firewire, and then sent
it over the network to VLC using parts of the DVSwitch suite.
(The video mixing rig and the server park are physically quite far apart.)
This has worked fine for our purposes, and we'll continue to use DV for
the other streams (and also as a backup for this one), but it's an
unneccessary part that probably adds a frame or three of latency on its
own, so it has to go.
Instead, we're going to send SDI directly into the encoder machine, and
multicast straight out from there. As an extra bonus, we'll have access to
the SDI clock that way; more on that in a future post.
Anyhow, you probably guessed it: VLC has no support for the Blackmagic
SDI cards we plan to use, or really any SDI cards. Thus, the first thing to
do was to write an SDI driver for VLC. Blackmagic has recently released a Linux
SDK, and it's pretty easy to use (kudos for thorough documentation, BM),
so it's really only a matter of writing the right glue; no reverse engineering
or kernel hacking needed.
I don't have any of these cards myself (or really, a desktop machine that
could hold them; I seem to be mostly laptop-only at home these days), but I've
been given access to a beefy machine with an SDI card and some test inputs
by Frikanalen, a non-commercial Norwegian TV station. There's
a lot of weird things being sent, but as long as it has audio and is moving,
it works fine for me.
So, I wrote a simple (input-only) driver for these cards, tested it a bit,
and sent it upstream. It actually generated quite a bit of an
email thread, but it's been mostly very constructive, so I'm
confident it will go in. Support for these cards seems to be a pretty much
sought-after feature (only VLC support for them earlier was on Windows, with
DirectShow), so a lot of people want their own “pony feature” in, but OK.
In any case, should there be some fatal issue and it would not go in, it's
actually not so bad; we can maintain a delta at the encoder side if we really
need to, and it's a pretty much separate module.
Anyhow, this post became too long too, so it's time to wrap it up. Tomorrow,
I'm going to talk about perhaps the most obvious sort of latency (and the
one that inspired the project to begin with — you'll understand what I mean
tomorrow), namely codec latency.
Tue, 05 Oct 2010 - VLC latency, part 1: Introduction/motivation
The Gathering 2011 is as of this time still announced (there's not even
an organizer group yet), but it would be an earthquake if it would not be held
in Hamar, Easter 2011. Thus, some of us have already started planning our
stuff. (Exactly why we need to so start early with this specific will be clear
pretty soon.)
TG has, since the early 2000s, had a video stream of stuff happening on the
stage, usually also including the demo competitions. There are obviously two
main targets for this:
People in the hall who are just too lazy to get to the stage (or have
problems seeing in some other way, perhaps because it's very crowded).
This includes those who can see the stage, but perhaps not hear it
too well.
People external to the party, who want to watch the compos.
Post-party use, from normal video files.
My discussion here will primarily be centered around #1, and for that, there's
one obvious metric you want to minimize: Latency. Ideally you want your stream
to appear in sync with the audio and video from the main stage; while video
is of course impossible, you can actually beat the audio if you really want,
and a video delay of 100ms is pretty much imperceptible anyway. (I don't
have numbers ready for how much is “too much”, though. Somebody can probably
fill in numbers from research if they exist.)
So, we've set a pretty ambitious goal: Run an internal 720p50 stream (TG
is in Europe, where we use PAL, y'know) with less than four frames (80ms)
latency from end to end (ie., from the source to what's shown a local end user's
display). Actually, that's measured compared to the big screens, which will
run the same stream, so compared to the stage there will be 2–3 extra frames;
TG has run their A/V production on SDI
the last few years, which is essentially based on cut-through switching,
but there are still some places where you need to do store-and-forward
to process an entire frame at a time, so the real latency will be something
like 150ms. If the 80ms goal holds, of course...
I've decided to split this post into several parts, once per day, simply
because there will be so much text otherwise. (This one is already more than
long enough, but the next ones will hopefully be shorter.) I have to warn
that a lot of the work is pretty much in-progress, though — I pondered waiting
until it was all done and perfect, which usually makes the overall narrative
a lot clearer, but then again, it's perhaps more in the blogging spirit to
provide as-you-go technical reports. So, it might be that we won't reach our
goal, it might be that the TG stream will be a total disaster, but hopefully
the journey, even the small part we've completed so far, will be interesting.
Tomorrow, in part 2, we're going to look at the intended base architecture,
the latency budget, and signal acquisition (the first point in the chain).
Stay tuned :-)